
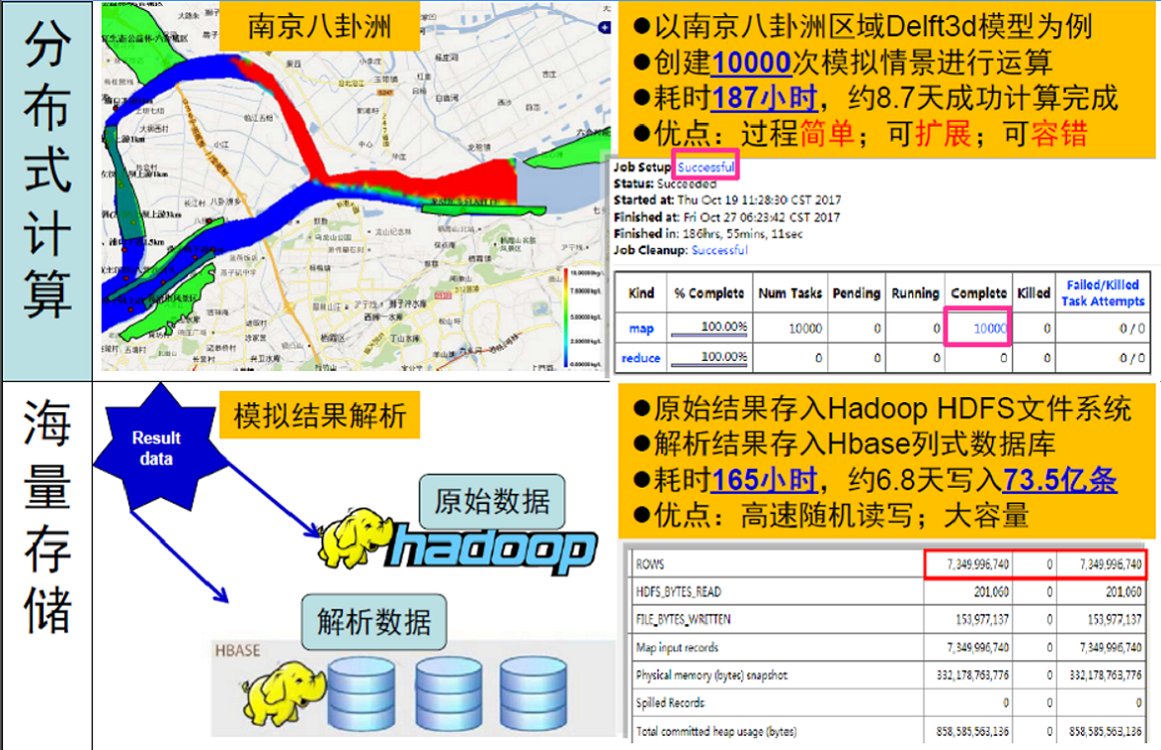
海量存储Hadoop集群
一、概念
大数据从获取到分析的各个阶段都可能会涉及到数据集的存储,考虑到大数据有别于传统数据集,因此大数据存储技术有别于传统存储技术。大数据一般通过分布式系统、NoSQL数据库等方式(还有云数据库)进行存储。
集群: 将多台服务器集中在一起,每台服务器(节点)实现相同的业务。因此每台服务器并不是缺一不可,集群的目的是缓解并发压力和单点故障转移问题。
分布式:传统的项目中,各个业务模块存在于同一系统中,导致系统过于庞大,开发维护困难,无法针对单个模块进行优化以及水平扩展。因此考虑分布式系统:将多台服务器集中在一起,分别实现总体中的不同业务。每台服务器都缺一不可,如果某台服务器故障,则网站部分功能缺失,或导致整体无法运行。因此可大幅度的提高效率、缓解服务器的访问存储压力。
分布式方便我们系统的维护和开发,但是不能解决并发问题,也无法保证我们的系统崩溃后的正常运转。集群则恰好弥补了分布式的缺陷,多个服务器处理相同的业务,这可以改善系统的并发问题,同时保证系统崩溃后的正常运转。分布式和集群技术一般同时出现,密不可分。
二、技术原理
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
配置和管理有实际意义的Hadoop集群,其规模可从几个节点的小集群到几千个节点的超大集群。安装Hadoop集群通常要将安装软件解压到集群内的所有机器上。通常,集群里的一台机器被指定为 NameNode,另一台不同的机器被指定为JobTracker。这些机器是masters。余下的机器即作为DataNode也作为TaskTracker。这些机器是slaves。我们用HADOOP_HOME指代安装的根路径。通常,集群里的所有机器的HADOOP_HOME路径相同。

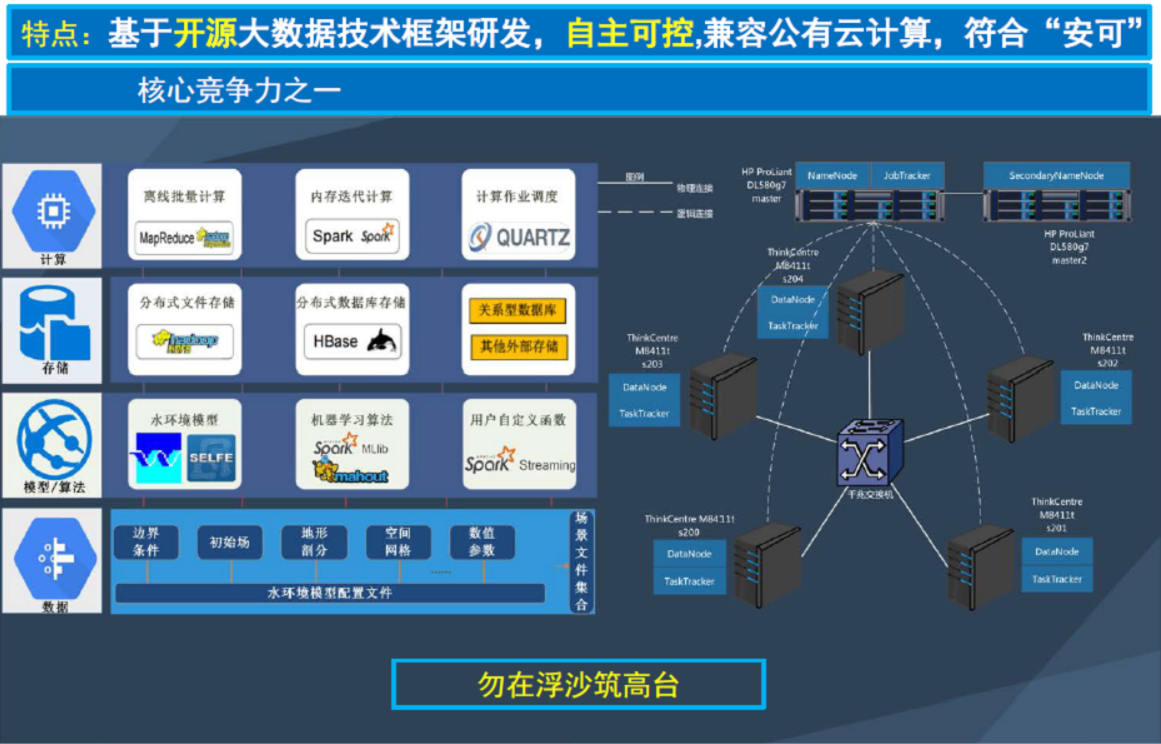
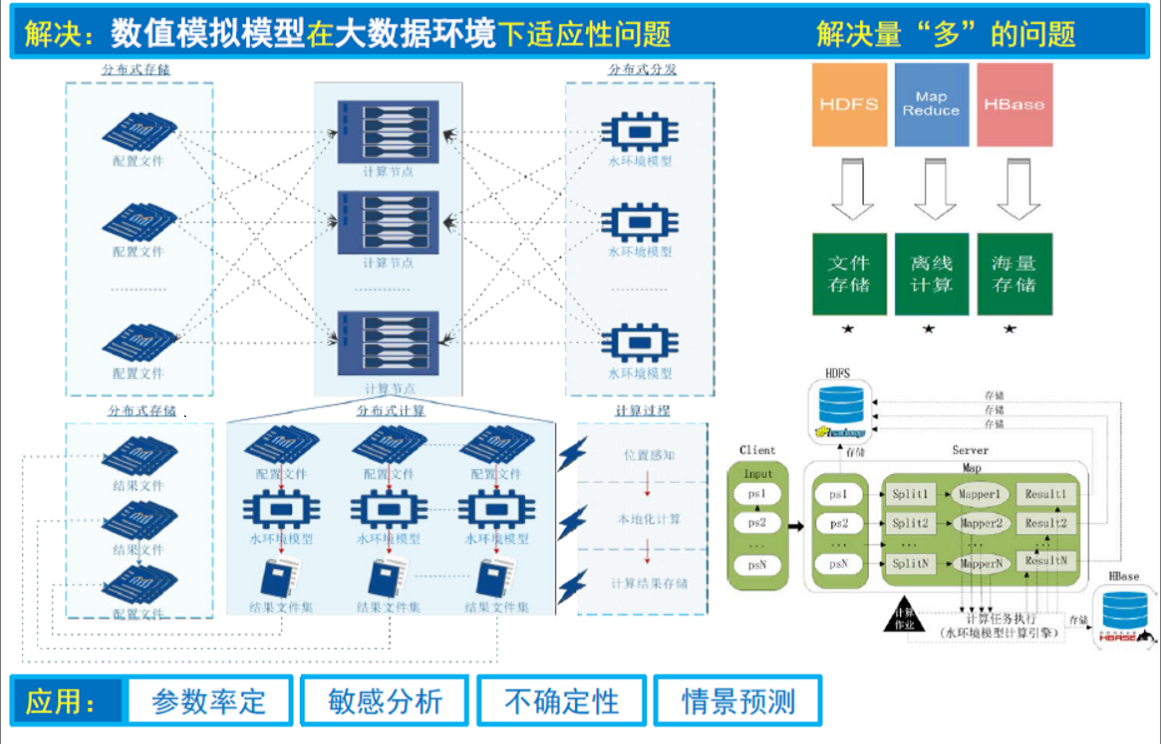
三、技术特点
1、专业专注
拥有安全可靠、简洁高效、架构归一的存储软件栈和稳定、安全、可靠的全栈硬件能力,持续不断技术研发及创新突破,满足不同客户需求
2、产品完善
基于完善的产品线,提供最适合业务应用的存储和场景化的解决方案,满足以“云、数、智”为技术应用背景的新数据时代下的创新发展与转型升级
3、业界领先
Hadoop集群即大数据技术的融合,致力于核心技术和产品的自主创新,在业绩遥遥领先。
四、应用范围
1、水环境模拟大数据平台
2、提供个性化服务定制版本
3、针对中小型企业、环保部门、分支机构的应用数据整合和数据共享的需求
实现对服务器的集中存储和管理,同时针对存储进行系统优化,提高存储性能。存储系统与数据相互独立,不占用数据存储空间;采用专用存储操作系统,保证系统存取的性能和可靠性。运行高速、大容量并便于将来扩容等,系统安装部署简单,使用和管理方便,提高数据可用性,整体性价比优异。