决策性服务
一、概念
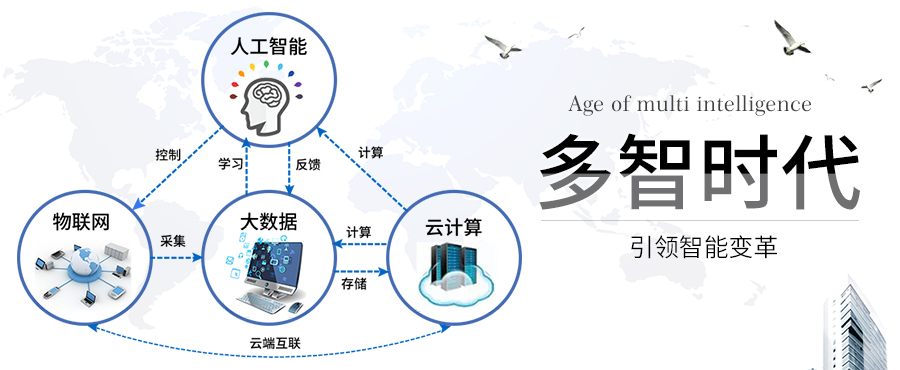
大数据=海量数据+复杂类型的数据。大数据具有大量化、多样化、快速化和价值化的特征,也称“4V”。其中:
大量化(volume)指数据量庞大,即数据存储量大、计算量大。
多样化(variety)指大数据不但包含结构化的数据表和半结构化的文本、视频、图像等信息,而且数据之间的交互也非常频繁和广泛。
快速化(velocity)指数据不断更新,增长速度快,同时数据存储、传输等的处理速度也非常快。
价值化(value)指数据正在成为一种新型资产、一种竞争力的重要基础。基于大量数据的分析和计算,可以产生更大的价值。
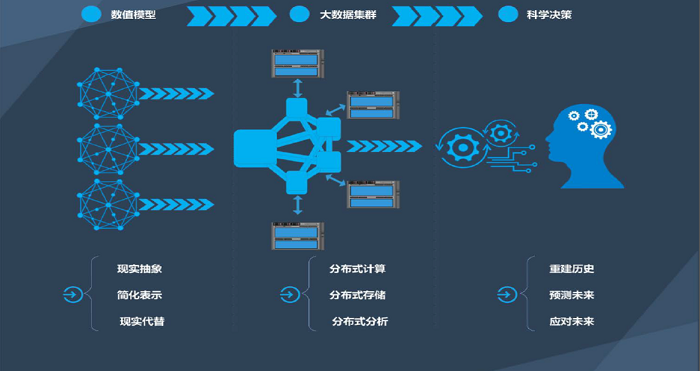
有研究表明,大数据的应用十分广泛,不仅能产生巨大的产业空间,也能产生巨大的社会价值。用大数据服务管理决策,将会在决策主体、决策方法、决策过程等方面发生革命性的改变,从而大大提高管理者的决策能力。
二、技术原理
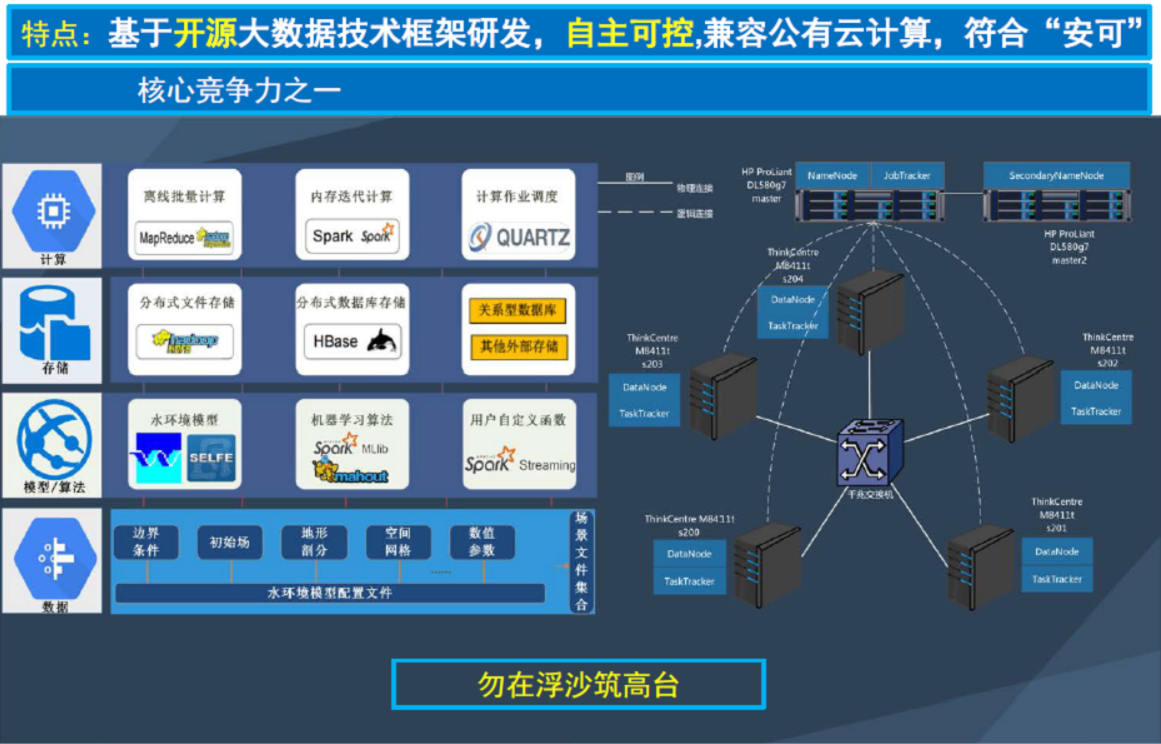
一、大数据应用技术
1、大数据搜索:Lucene、Solr、ElasticSearch。ElasticSearch是新推出的比Solr在大规模数据情况下更好的开源解决方案。
2、大数据查询:这里有Hive/Impala,Hive的作用是你可以把结构化数据导入到Hadoop中然后用简单SQL来做查询。你可以把Impala看做是性能更快的Hive,因为Impala不强依赖MapReduce。而Facebook开源的Presto更是能查询多种数据源,而且一条Presto查询可以将多个数据源的数据进行合并。
3、大数据分析:咱们要提到去年新晋顶级Apache项目的Kylin。它创始于ebay,2014年进入apache孵化项目。Kylin不仅仅能做SQL查询,而且能做Cube多维分析。
4、大数据挖掘:这个领域包含精准推荐、机器学习/深度学习/神经网络、人工智能。自从AlphaGo火了以后,机器学习再度火热。Google开源了最新机器学习系统TensorFlow,微软亚洲研究院开源了分布式机器学习工具包-DMTK,雅虎也开源了Caffe On Spark 深度学习。Mahout是Apache的一个开源项目,提供一些机器学习领域经典算法的实现,包括聚类、分类、推荐过滤、频繁子项挖掘。
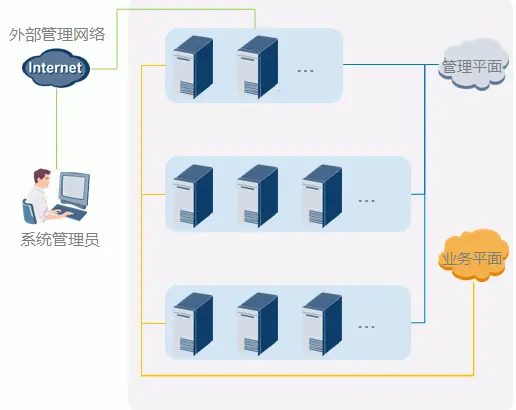
二、技术平台建设
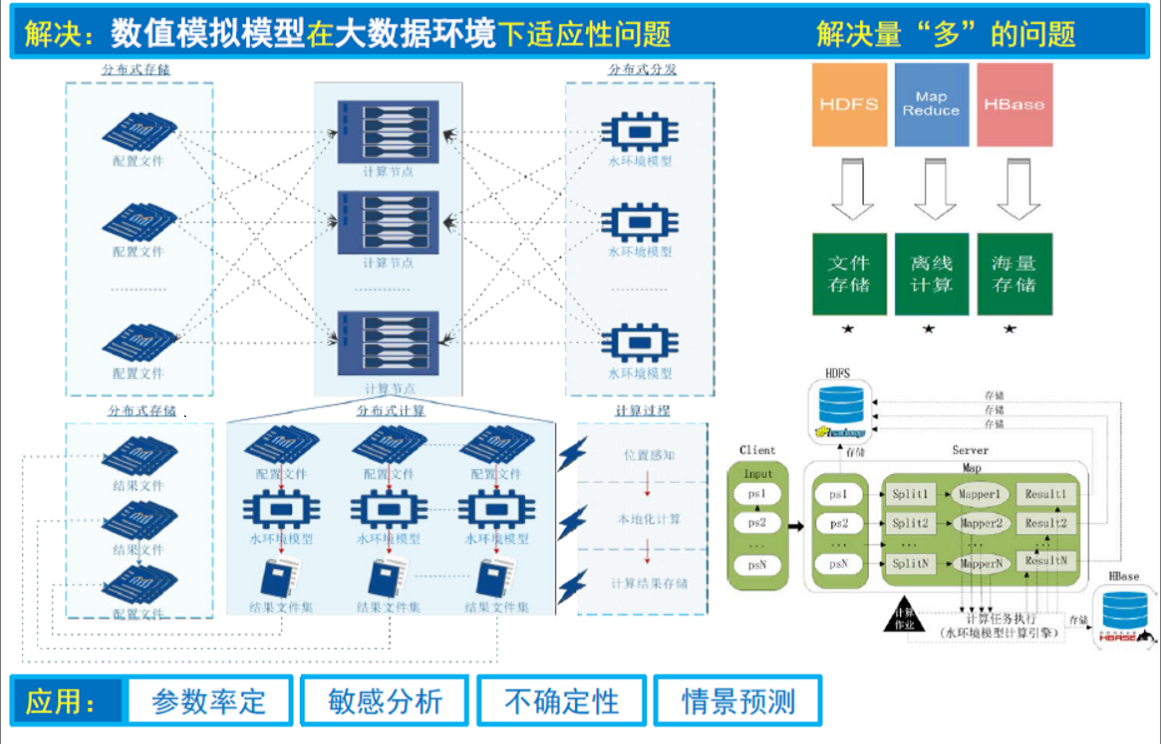
1、大数据基础架构:推荐Hadoop、HDFS、YARN;大数据计算框架:推荐Spark;大数据日志收集推荐Flume+Logstash+Kibana。我们需要部署依赖中间件Zookeeper。
2、大数据仓库平台建设:分布式关系型TiDB、KV式Redis、文档型MongoDB、列式Hbase
3、大数据搜索,推荐选择Lucene、ElasticSearch;大数据查询,推荐选择Presto;大数据多维分析,推荐Kylin;大数据挖掘,推荐挖掘开源算法包MashOut。
三、大数据整理服务
1、主数据管理:主数据标准制定、主数据清洗与校验、主数据转换(拆分合并)、主数据复制分发、主数据访问OpenAPI。
2、ETL:数据抽取、数据清洗、数据校验、数据安全脱敏
四、大数据分析系统建设
1、大数据展示平台建设
2、大数据商业应用模型建模
3、大数据应用分析系统设计与开发
三、技术特点
1、智能预警监控所有突发情况
拥有安全可靠、简洁高效、架构归一的存储软件栈和稳定、安全、可靠的全栈硬件能力,持续不断技术研发及创新突破,满足不同客户需求。任何异常情况的发生,都可以随时通知,效率翻倍。
2、规范化数据管理,让运营更放心
规范化数据管理,提供最适合业务应用的存储和场景化的解决方案,满足以“云、数、智”为技术应用背景的新数据时代下的创新发展与转型升级,让运营更放心安全。
3、拥有大数据能力
Hadoop集群即大数据技术的融合,致力于核心技术和产品的自主创新,拥有大数据能力。
四、应用范围