高性能计算
一、概念
高性能计算集群(HPCC-High Performance Computing Cluster)是计算机科学的一个分支,以解决复杂的科学计算或数值计算问题为目的,是由多台节点机(服务器)构成的一种松散耦合的计算节点集合。为用户提供高性能计算、网络请求响应或专业的应用程序(包括并行计算、数据库、Web)等服务。相比起传统的小型机,集群系统有极强的伸缩性,可通过在集群中增加或删减节点的方式,在不影响原有应用与计算任务的情况下,随时增加和降低系统的处理能力。还可以通过人为分配的方式,将一个大型集群系统分割为多个小型集群分给多个用户使用,运行不同的业务与应用。集群系统中的多台节点服务器系统通过相应的硬件及高速网络互连,由软件控制着,将复杂的问题分解开来,分配到各个计算节点上去,每个集群节点独立运行自己的进程,这些进程之间可以彼此通信(通常是利用MPI-消息传递接口),共同读取统一的数据资源,协同完成整个计算任务,以多台计算节点共同运算的模式来换取较小的计算时间。
根据不同的计算模式与规模,构成集群系统的节点数可以从几个到上千个。对于环保机构和中小型公司来讲,节点数目可以达到数千甚至上万。而随着HPCC应用的普及,中小规模的高性能计算集群也慢慢走进中小型用户的视野,高性能计算集群系统的部署,极大地满足了此类用户对复杂运算的能力的需求,大大拓展了其业务范围,为中小型用户的成长提供支持。
二、技术原理
计算节点用于科学计算,运行并行计算程序,是高性能集群计算系统的主体。
1、数据仓库
各式各样的数据,经由各种上层应用进行了采集和存储。但我们一提到大数据,自然想到的就是大数据分析。大数据分析的第一步就是大数据仓库建设。大数据仓库建设,必要的工作就是ETL(抽取、转换、导入)。抽取,这步就又细分为:数据抽取、数据清洗、数据校验。在转换这步,我们也需要关注数据安全脱敏,也就是说,进入大数据仓库的数据需要分级。
2、大数据仓库基础架构
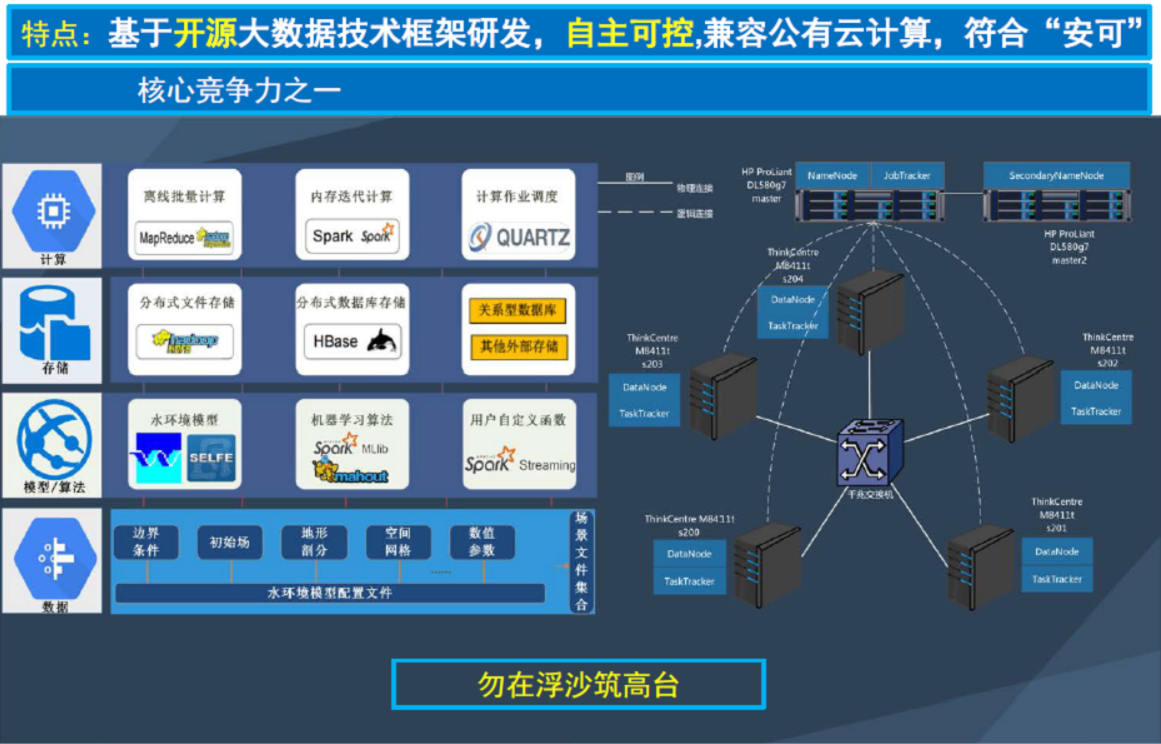
现在建大数据仓库,需要的是分布式存储和分布式计算,再也不是过去几十台服务器和几百T存储这么简单的。这都是要以万计的,这才是真正的大数据。而要建造这么大规模的大数据仓库,需要分布式存储和分布式计算基础框架支撑。
我们第一个就要提出的就是Hadoop。目前它已经成为了一个生态。Hadoop最核心是两块:分布式文件系统HDFS、MapReduce。MapReduce又分为MAP(分解任务)、Reduce(合并结果)两部分。
3、大数据计算框架
在大数据处理领域,目前当红炸子鸡是:Spark、Storm、Flink。
Spark切的领域在MapReduce工作的领域,不过Spark大量把MAP中间结果放到内存中,所以显得性能特别快。现在Spark也在往生态走,希望能够上下游通吃,一套技术栈解决大家多种需求,所以大家又渐渐看不清楚Spark聚焦的领域了。Spark Shark,是为了VS hadoop Hive,Spark Streaming是为了VS Storm。
Storm擅长处理实时流式。比如日志,比如网站购物的点击流,是源源不断、按顺序的、没有终结的,所以通过Kafka等消息队列来了数据后,Storm就一边开始工作。Storm自己不收集数据也不存储数据,随来随处理随输出结果。
三、技术特点
1、管理
通过HP CMU, 您可以暂停、启动、重启或关闭选定的任何节点。您还可以连接到集群中的多个节点, 并通过一次键盘输入以广播的方式向其发出命令。HP CMU也可以帮助您管理来自集群的事件,如节点的增加或减少等。
2、克隆
对于初次安装或者未来更新, 集群管理员能够向集群中所有或部分计算节点传送系统配置映像。CMU是唯一一款经实际检验能高效管理1000个以上计算节点的管理工具。
3、监控
凭借其新的监控特性, 整个集群的环境和性能信息可作为一个系统向系统管理员呈现。管理员能够对整个系统的表现一目了然, 而无需对单独计算节点
四、应用范围